大数据安全分析:我们从日志中得到的(二)
访问可视化和安全可视化一直以来都是困扰我的一个难题,对于我们码农来说,各种各样的print出来的信息表格已经足够,但是领导可就不这么认为了(汗),对于领导来说,他能看到的,肯定是一个很炫酷的图,什么样的攻击,从哪里来,一定要直观!无奈只能自己动手丰衣足食。
先看看效果:

使用Google map +python来进行IP访问实时展示,整个架构是这样的:
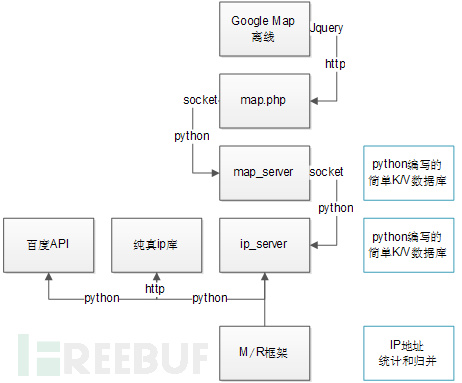
简单介绍下几个重要组件的功能:
首先是M/R的计算框架,使用map.py和reducer.py,从IIS日志中准实时对所有访问请求的IP地址进行一个统计,过去1分钟,每个IP访问了多少次,然后将结果归并,最后得到一个IP访问的排名Clientip.csv,每行前面是IP,后面是访问次数,如:
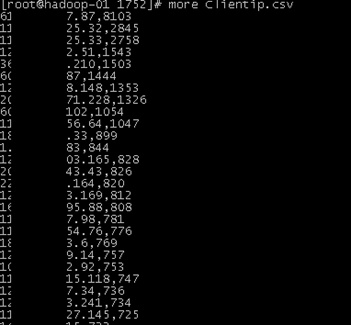
这个M/R的计算是使用自动化python脚本实时跑的,脚本截取如下:
import sys,os,time
#/IIS_LOG/14-02-13/1753
LAST_TASK = ""
def main():
global LAST_TASK
daylist = os.popen("hdfs dfs -ls /IIS_LOG/").read().split("\n")[-2].split(" ")[-1]
taskpath = os.popen("hdfs dfs -ls "+daylist).read().split("\n")[-3].split(" ")[-1]
print taskpath
#M/R start
if taskpath != LAST_TASK:
task = os.popen("python run.py "+taskpath).read()
#M/R stop
if task.find("Done") != -1:
LAST_TASK = taskpath
return
while 1:
main()
time.sleep(5)
~
每个15秒,对hadoop中的日志目录进行检查,对最新一天的倒数第二个文件夹进行调用M/R任务下发脚本run.py进行分析。
Run.py的代码如:
import os,sys
JOB_INPUT=sys.argv[1]
print JOB_INPUT
JOB_OUTPUT='/IIS_LOG_OUTPUT/'+sys.argv[1]
HADOOP_TOOL="/usr/bin/hadoop"
HADOOP_STREAM="/opt/cloudera/parcels/CDH/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.0.0-mr1-cdh4.4.0.jar"
MAPPER="mapper.py"
REDUCER="reducer.py"
def clear_job():
os.system(HADOOP_TOOL+" dfs -rm -r "+JOB_OUTPUT)
def run_job():
os.system(HADOOP_TOOL+" jar "+HADOOP_STREAM+" -file "+MAPPER+" -file "+REDUCER+" -mapper 'python mapper.py' -reducer 'python reducer.py' -input "+JOB_INPUT+" -output "+JOB_OUTPUT+" -numReduceTasks 12")
def get_result():
os.system(HADOOP_TOOL+" fs -copyToLocal "+JOB_OUTPUT+" .")
out = os.path.split(sys.argv[1])[-1]
os.popen("python deal.py "+out+"/ &")
print "Done"
clear_job()
run_job()
get_result()
下发M/R任务后,会调用deal.py进行结果的整合和输出,deal.py的输出也就是Clientip.csv.
最后调用一个Clientip.py来进行我们的IP访问结果的输出,代码如:
import os,sys,time
import socket
def main():
conn_in = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
conn_out = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
conn_out.connect(('127.0.0.1',50002))
conn_in.connect('127.0.0.1',50005))
file = ''+sys.argv[1]+'/Clientip.csv'
data = open(file,'r').readlines()
sl = float(60)/len(data)
for line in data:
line = line.strip().split(",")[0]
conn_in.send(line+'\n')
data = conn_in.recv(10240)
if len(data)>20:
conn_out.send(data+'\n')
tmp = conn_out.recv(3)
time.sleep(sl)
return
main()
根据我前面给出的逻辑架构图不难看出,127.0.0.1:50002是一个ip_server,也就是一个IP的geo地理位置的查询服务器,这个是用python实现的一个简答K/V数据库,逻辑如下:
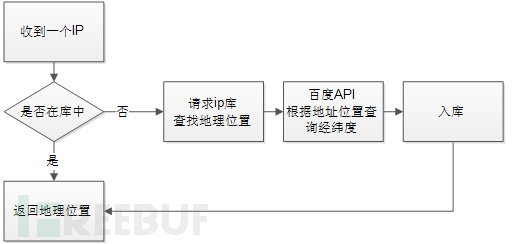
相关代码可以在这里找到:
前台使用的是google的离线map,采用google的API在地图上绘制mark标记,设定了一个定时器timmer,每隔一秒调用map.php,map.php的作用是从map_server中定期读取目前在线的ip列表,然后转换成json的格式,输出给javascript进行整理,代码如下:
<?php
$service_port = 80;
$address = '127.0.0.1';
$socket = socket_create(AF_INET, SOCK_STREAM, SOL_TCP);
if ($socket === false) {
echo "socket_create() failed: reason: " . socket_strerror(socket_last_error()) . "\n";
} else {
}
@$result = socket_connect($socket, $address, $service_port);
if($result === false) {
echo "{}";
} else {
$result = "";
while ($out = socket_read($socket, 1024)) {
$result.=$out;
}
socket_close($socket);
if ($result == NULL)
{
die();
}
echo $result;
}
?>
然后就是Google map的API了,调用api显示mark的时候,为了防止过度刷新(每次都刷新全部的mark标记),需要在内存中建立一个数组,每次获取到新的IP数组信息时,与这个数组进行比对,将已经消失的IP的marker删除,然后添加新的marker标记,核心代码如:
function flush(){
var tmp = new Array();
$.post("map.php",{},function(data){
for (var i in data)
{
line = data[i];
tmp.push(line["ip"]);
if (line["ip"] in markers )continue;
var latlng = new google.maps.LatLng(line["lat"],line["lng"]);
var marker = new google.maps.Marker({position: latlng, map: map,draggable: true,title: line["ip"]+":"+line["addr"]});
markers[line["ip"]] = marker;
}
tmp1 = {};
for (var j in markers)
{
if ($.inArray(j,tmp) == -1)
{
markers[j].setMap(null);
}else
{
tmp1[j] = markers[j]
}
}
markers = tmp1;
},"json");//这里返回的类型有:json,html,xml,text
}
然后我们的map_server.py中,进行了IP访问的超时机制设定,在接受到新的IP时,固定一个超时时间,如果IP再次出现,就给予重新设定超时,如果长时间没有访问,就将这个IP从在线列表中祛除,最后输送给map.php。
本质上map_server.py是GoogleMap的一个二级缓存服务器,把IP访问的超时机制和临时存储从javascript中释放出来,而让javascript只处理显示问题,map_server.py和map.php是直接通过socket来连接的,数据格式是json,其实内存中就是一个字典表格
| IP地址(索引) | IP地理位置 | 超时 |
| 1.1.1.1 | {“lat”: 22.929986, “ip”: “1.1.1.1”, “lng”: 11.395645, “addr”: “深圳市”} | 30 |
| 2.2.2.2 | {“lat”: 11.929986, “ip”: “1.1.1.1”, “lng”: 33.395645, “addr”: “深圳市”} | 30 |
使用threading的多线程来进行数据插入和刷新。
这样我们就完成了由多级架构组成的IP访问显示,当然,数据源的M/R框架完全可以替换成类似tcpdump或者snort做采集提高实时性,同时我这里是每个IP显示一个点,如果访问IP过多的话,就会让浏览器很慢,并且显示很密集,因此大家完全可以提前按照省市做一次归并,然后通过控制google map api的marker大小和颜色,来进行更直观的输出,我这里就不再细说了^_^
同时,经过测试,当我的ip_server接受超过了50W个IP后,本地存储的文件db已经达到了80M,使用python直接读取,转换成json的时间高达13秒,已经不可接受了,所以必须将ip_server进行改进,这里给出一种解决方案,使用redis内存数据库,将原有的IP_DATA.db迁移到redis数据库的脚本为:
import socket
conn = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
conn.connect(('127.0.0.1',50005))
fi = open('Clientip.csv','r')
for line in fi.readlines():
line = line.split(",")[0]
conn.send(line+'\n')
data = conn.recv(1024)
改进后使用redis数据库的ip_server.py的代码,可以在这里找到。
如果大家有什么建议或者更好的解决方案,欢迎和我讨论^_^
在下一篇文章中,我会继续介绍使用M/R对IIS日志的分析情况。